
10 minute reading time; ~1840 words
Greetings!
By the time we got to the end of our last post, we had:
- Developed some user stories and requirements.
- Created wireframes for a few of the tools.
- Detailed a workflow.
Today, we’re going to transition into technical work and start developing our system design. This work will lay the foundation for understanding how everything fits together and translates into an actual app.
If you haven’t read the previous posts, I’d suggest you start at An App From Scratch: Part 1 – What To Build. You can also find all the related documents and code here: Building Tailgunner.
System Design
If this project has been well-run, there’s already been a technical consultant (a developer, staff engineer, or technical engineering manager) involved in some of the previous planning work. Now, this is where the project planning becomes the responsibility of the developer(s) assigned to lead the project implementation. The development team will take the information they’ve been given and move into system design.
System design: the process of defining the structure, components, and interactions needed for the app to be able to fulfill the requirements we’ve been putting together.
In the case of our project, even though we haven’t completely defined all the details for all of our user stories, that’s not required, as it’s an iterative process and the design will evolve as details become finalized.
We’re going to talk about overall architecture, and then dive into a few components:
- Database designs
- API endpoints
- Data flows
- Error handling
Let’s get started!
Overall Architecture
There are a few different choices we could make about the architecture to support these tools.
To Monolith Or Microservice
The first choice we have to make is if we want a monolith or microservice architecture. Knowing your constraints early can help with this kind of decision-making. Since I’m working as a solo developer and don’t expect this app to be a high-traffic service, I’m going to build a monolithic service.
Remember, whichever choice you make, you’re not locked in forever, and you can always change as the needs of the service evolve, so there’s no need to make the perfect decision from step one.
One of the biggest advantages to a monolith is that it’s a lot simpler to develop, build, deploy, and manage. However, if I expected to have to service a high volume of users, needed to scale different parts of the system at different rates, or had multiple teams working on the project, some or all of the tool might be better suited to the microservice pattern instead.
Now with that decision made, we can talk about the next design piece: data.
Tech Stack
We’re going to make some easy decisions here. My main goal with this project is to refresh myself on some specific technologies, so we’re going to use:
- Backend: Laravel (a PHP framework)
This framework is one of the most popular for PHP, and will easily support long-term growth. With the starter kit, I get a lot of functionality out of the box, including login and user pages, API support, and even niceties like dark mode. - Frontend: Vue.js / Inertia
Installed as part of Laravel, this stack gives us the ability to easily create single-page apps, and with the starter kit, it comes baked into Laravel, saving me time. - Database: MySQL
One of the most used database servers, I’ve worked with this for years, it scales well when needed, and easily integrates with Laravel. - API: REST
One of the most common API protocols, and also the most simple to work with, it’s the best choice for a project of this scale. - Other tools: Redis for caching
Redis is a flexible cache technology, and Laravel uses it by default. This will give us the tooling needed to make our app faster if we find bottlenecks in data access.
Since this is a solo project, with no need for a complex infrastructure, these choices let me hit the ground running, and also leave room for future expansion.
Database Designs
Having a look at our project plan again, the tool we’ve detailed is to manage templates for data input, which leads to defining how the template structure and metadata will be saved.
Table: templates
| Field Name | Field Type |
|---|---|
| id | Primary Key |
| user_id | Foreign Key, Index |
| title | String |
| description | Text, Nullable |
| created_at | Timestamp |
| updated_at | Timestamp |
| deleted_at | Timestamp |
Table: template_fields
| Field Name | Field Type |
|---|---|
| id | Primary Key |
| template_id | Foreign Key, Index |
| label | String |
| name | String |
| type | String |
| order | Integer |
| extended_options | Text, Nullable |
| created_at | Timestamp |
| updated_at | Timestamp |
| deleted_at | Timestamp |
When creating a new template, a record will get created in the templates table. As we edit the template fields, we’ll be updating the records in the template_fields table, including the special data field extended_options (where we can store details on exactly how the field works, like the options in a dropdown).
You can also see here that we’re recording the user_id on the template, so we know who owns the template, and for each of the template fields, we’re storing the template_id they belong to.
These two tables address all the needs from US1, as well as enabling soft-deletes for both templates and fields in them (which will allow us to undo deletes if needed).
API Overview
Now that we know what our database is going to look like, it’s time to figure out what API endpoints we’re going to need to support the project.
NOTE: Because we’re using Inertia, we don’t actually need API endpoints, but we’re going to pretend that we do for the purposes of this post. You’d need to do this if you had a mobile app, or were using something like React.
Based on the workflows that we broke out in the last post, our API will need to support the following:
- Create a template
- Get template (metadata and fields)
- Update a template (metadata and fields)
- Delete a template
- Clone a template
From this list of actions, it’s easy already to map out what API endpoints we’re going to need to support the workflows (bonus, some of these endpoints will also support other workflows).
We’re going to make an assumption that we’re only going to save the changes when the user actually clicks save. If this weren’t the case, we might also need additional endpoints to support saving as the user makes changes:
- Get template metadata
- Update a template metadata
- Get template fields
- Create template field
- Update template field
- Delete template field
Now that we have a list of actions we need to support, let’s map those into the REST verbs and a list of actual endpoint URLs.
What’s REST And A REST Verb?
REST (Representational State Transfer) is a software architectural style designed to guide the development of web interfaces. It gives developers a standard way to think about API design, and makes it easier for services to interconnect over the Internet.
As an example of how your computer already works today, when your web browser requests a page, it’s using a GET action, and when the server responds, it’s passing a chunk of (usually) text or image data, along with a status code of 200 (Success). The other one you might be familiar with is a 404 (Not Found), but there are roughly 60 status codes to help your browser understand the status of the response.
Some common HTTP codes used in REST are:
Request Successful
- 200: Success
- 201: Created
- 204: No Response Data
Client Error
- 400: Bad Request
- 401: Unauthorized
- 403: Forbidden
- 404: Not Found
- 409: Conflict
Server Error
- 500: Internal Server Error
- 503: Service Unavailable
There are 5 REST verbs that are most commonly used, and they’re defined by actions already available in the specifications for HTTP (the protocol that defines how your computer talks to a web server). They also respond with common HTTP status codes, making this kind of API very easy to understand from a technical perspective.
| Verb | Action | Success | Failure |
|---|---|---|---|
| GET | Gets some data from the server. This might be single record, or a list of them. | 200 | 404 |
| POST | Create a new record, or multiple records. | 201 | 404, 409 |
| PUT | Replace a specific record (full update). | 200, 204 | 404 |
| PATCH | Update a record (partial update). | 200, 204 | 404 |
| DELETE | Deletes a record. | 200 | 404 |
If you want to dive deeper, you can start here: What Is a REST API? Examples, Uses, and Challenges
API Design
There are a couple of ways you can do versioning: URL, query parameter, or custom header. The simplest one is via the URL, which you’ve likely seen before (/api/v1/, /api/v2/, etc), and that’s what we’re going to use as the basis for our API.
With that in mind, let’s create some API endpoints! First, here are the actions, and how they line up to an API design.
| Action | API URL | Verb |
|---|---|---|
| Create a template | /api/v1/template | POST |
| Get template (metadata and fields) | /api/v1/template/{id} | GET |
| Update a template (metadata and fields) | /api/v1//{id} | PUT |
| Delete a template | /api/v1//{id} | DELETE |
| Clone a template | /api/v1/ | POST |
Now, let’s detail an API endpoint more, with some expected data structures.
NOTE: This section uses a simple JSON format for readability. If I were working on this documentation for review by a developer team, or as an artifact to be used in the development process, I’d switch to OpenAPI documentation, as this would allow us to generate end-user documentation or mock API endpoints for testing.
Action: Create a template
URL / Verb: /api/v1/template : POST
Payload
{
"name": "String; The name of the template"
}Response
Status: 201
Location: https://tailgunner.app/api/v1/template/{id}
Content-Type: application/json{
"id": "Integer; The ID of the template we created"
}Now that we’ve walked through designing an API endpoint, the next step is to understand how everything fits together. The API is the backbone of communications, and in the next section we’re going to create a diagram to connect all the pieces together, and illustrate how they interact and bring the application to life!
Diagramming The System
As they say, a picture is worth a thousand words, and in this case, a diagram can connect all the pieces so we can see the system. There are many tools that can be used for making diagrams, depending on your needs, but my personal favorite is Lucidchart.
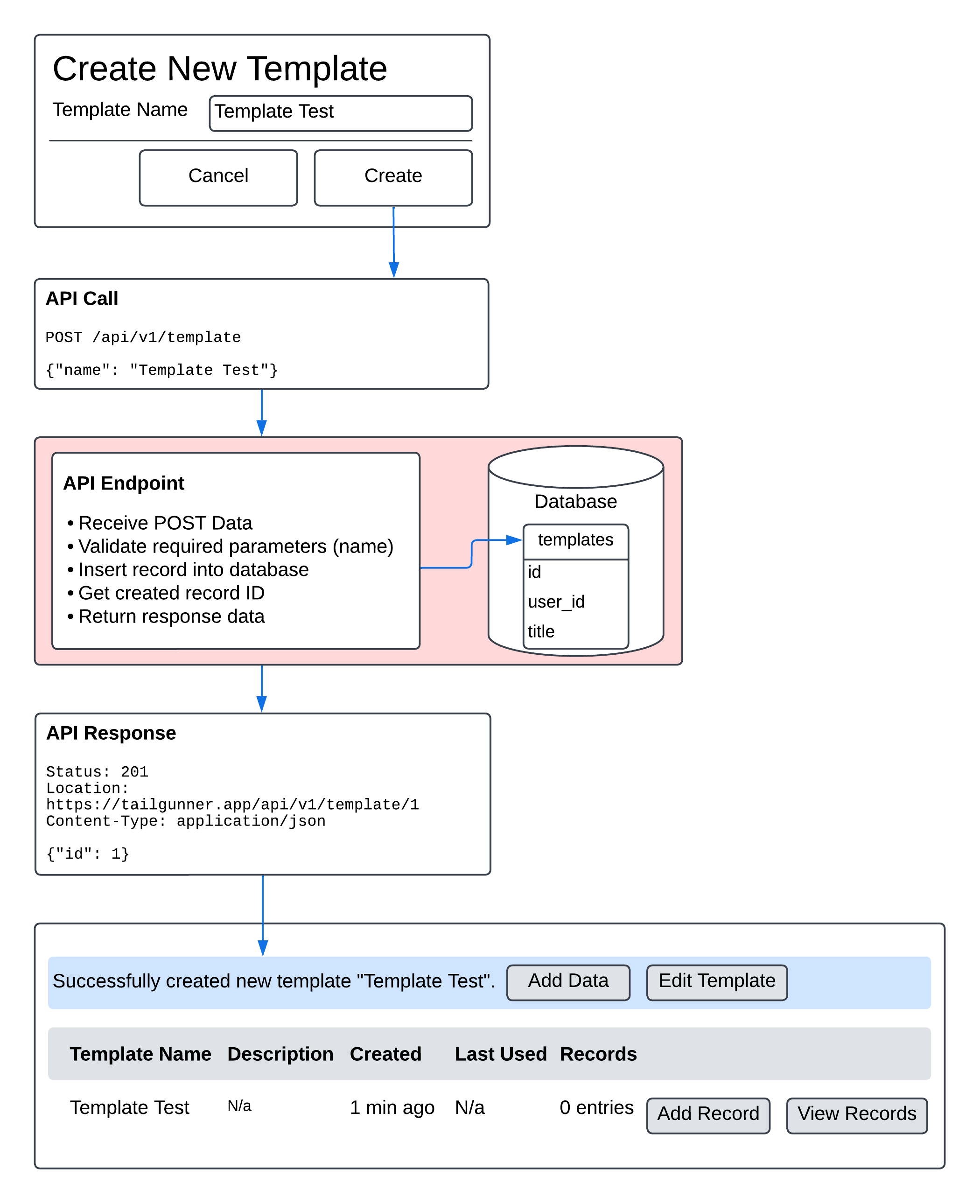
As you can see, even a simple workflow like creating a new template has a lot of moving parts. By taking the time to diagram a process like this, we get a better understanding of how all the pieces fit together, and create a shared vision for the project team, to make sure they’re aligned before spending a bunch of time building.
Wrapping It Up
From this chapter in our project design, we’ve explored the basics of the system, sketching out the beginnings of both a database and API, as well as diagramming a complete (simple) workflow from one end of the system to the other. This process has helped us establish the start of our technical design, and given us a clear structure to expand out to a full plan.
Did I miss something in my system designs? Share your thoughts in the comments below!
Thanks for taking the time to read this, and stay tuned for the next part: development planning.
Cheers!
Leave a Reply