
9 minute reading time; ~1780 words
Greetings!
Now that we’ve done our planning, we’re at the part where the rubber meets the road. In this post (and the next few), we’re going to implement the actual cards that we’ve put together.
Along with walking through how to execute the card, we’re also going to cover the branching and pull request processes, to give you an idea of the mechanics of getting code from our own system into the production codebase.
While these posts are more technical in nature, I’m going to explain what I’m doing, so that anyone can follow along!
If you haven’t read the previous posts, I’d suggest you start at An App From Scratch: Part 1 – What To Build. You can also find all the related documents and code here: Building Tailgunner.
What Do I See?
As a developer, when we start working on a card, we usually break down what we want to do in our head, or on a scrap of paper, or in our notes, but there is some translation of “what the card wants” into “what I need to do”. With that in mind, let’s look at the card to break it down.
Card: US1-C1
Title
Create database tables
Type
Task
Description
Create the database tables required to support creating a template and store their fields.
Acceptance Criteria
- The database tables from the defined data model exist.
- The models required to access these tables exist and are working.
Details
See the tables documented in the technical plan.
What I Need To Do
- Create new migrations and models for tables
This task will define the structure of the database tables via code (the migration). These migrations will allow us to change what’s in the database automatically, making it reproducible. As well, we’ll define models, which are Laravel classes that enable the tool to interact with each table we create. - Define the relationships between tables
In each model, we’ll define any relationships with other tables, allowing us to use the query builder more effectively (since it will understand how to connect one table to another). - Create seed data
We’re going to set up some seeders for our tables, so that we have some data for development and testing. These seeders will allow us to repopulate the database tables from scratch whenever we want to. - Run the migrations
Now that we have defined tables and seeders, we’re going to execute them, so the tables are created and populated. - Examine the generated tables
With the table creation completed, the last thing to do is have a look at the tables themselves. This is a quality check to make sure that the structure is what I expect, and what makes sense for the data and purpose. If anything doesn’t feel right, this is our chance to adjust the migrations and try again.
Putting It Into Action
Create new migrations and models for tables
First, let’s generate some models. Along with them, we’re also going to add some factories along with our seeders to help generate sample data, and add in the controller for the template, so we have an easy on-ramp to create our API later on.
php artisan make:model Template --migration --factory --seed --controller
php artisan make:model TemplateField --migration --factory --seedThis command will create these files (except the migration file names might be different):
app/Http/Controllers/TemplateController.php
app/Models/Template.php
app/Models/TemplateField.php
database/factories/TemplateFactory.php
database/factories/TemplateFieldFactory.php
database/migrations/2025_01_05_011700_create_templates_table.php
database/migrations/2025_01_05_011708_create_template_fields_table.php
database/seeders/TemplateFieldSeeder.php
database/seeders/TemplateSeeder.phpDefine the relationships between tables
With our two new models, we need to set up a few relationships, so Laravel understands how to enable our access between the tables. Here’s how our database models relate to each other.
| User | Template | TemplateField |
|---|---|---|
| Has Many TemplateField | Belongs To User | Belongs To Template |
| Has Many TemplateField |
Each of these relationships is defined in the model code for the table, for example:
class Template extends Model {
public function user() {
return $this->belongsTo(User::class);
}
public function fields() {
return $this->hasMany(TemplateField::class);
}
}This code will make the template fields accessible via a fields property when we access a template, which when accessed will give you all the fields associated with this template, as you can see below.
$fields = $template->fields;Create seed data
Earlier, we created seeders, but also factories to better encapsulate the logic required to create a new record. Here’s the factory I set up for the template model. As you can see, it’s passing back fake data generated from both the factory for the user, as well as specific fields using the Faker library.
class TemplateFactory extends Factory {
public function definition(): array {
return [
'user_id' => \App\Models\User::factory(),
'title' => $this->faker->sentence(3),
'description' => $this->faker->paragraph(2),
'created_at' => now(),
'updated_at' => now(),
'deleted_at' => null,
];
}
}Now that we have a factory, we also have to update the model to add the HasFactory trait, so that the model can be used as part of factory operations.
class Template extends Model {
use HasFactory;
public function user()
public function fields()
}Let’s set up the seeder as well. This code will use the template factory we created to create 10 new records in the database when we run it.
use App\Models\Template;
class TemplateSeeder extends Seeder {
public function run(): void {
Template::factory()->count(10)->create();
}
}To wrap this piece up, this is how it all works.
We ask Laravel to seed the table, the seeder uses the factory (called through the model) to generate fake data, then the model is used to write the generated data into the table.
Run the migrations
This is the easy part: running the migrate command and one of our seeders. These migrations make sure that the database matches our requirements, while the seeder makes sure we have some data to test with.
The TemplateField seeder will call our Template factory, since every field needs to have a template. This will also populate associated users, since the Template factory also needs users to own the templates.
ben@phpbox:~/tailgunner/src$ php artisan migrate
INFO Running migrations.
2025_01_05_011700_create_templates_table ................ 352.55ms DONE
2025_01_05_011708_create_template_fields_table .......... 607.51ms DONE
ben@phpbox:~/tailgunner/src$ php artisan db:seed --class=TemplateFieldSeeder
INFO Seeding database.As part of running the migrations, Laravel will also write records to the migrations table, so it can track what changes we’ve applied to the database.
Examine the generated tables
Previously, we could have used the --pretend flag with our migrations (before we ran them) to see the SQL that Laravel would have run to change our database. Now that we’ve run them and the seeder as well, we can connect to the dev database and review the tables with data in them.
mysql> SHOW TABLES;
+------------------------+
| Tables_in_tailgunner |
+------------------------+
| cache |
| cache_locks |
| failed_jobs |
| job_batches |
| jobs |
| migrations |
| password_reset_tokens |
| personal_access_tokens |
| sessions |
| team_invitations |
| team_user |
| teams |
| template_fields |
| templates |
| users |
+------------------------+
mysql> DESCRIBE templates;
+-------------+-----------------+------+-----+---------+----------------+
| Field | Type | Null | Key | Default | Extra |
+-------------+-----------------+------+-----+---------+----------------+
| id | bigint unsigned | NO | PRI | NULL | auto_increment |
| user_id | bigint unsigned | NO | MUL | NULL | |
| title | varchar(120) | NO | | NULL | |
| description | text | YES | | NULL | |
| created_at | timestamp | YES | | NULL | |
| updated_at | timestamp | YES | | NULL | |
| deleted_at | timestamp | YES | | NULL | |
+-------------+-----------------+------+-----+---------+----------------+
mysql> DESCRIBE template_fields;
+------------------+-----------------+------+-----+---------+----------------+
| Field | Type | Null | Key | Default | Extra |
+------------------+-----------------+------+-----+---------+----------------+
| id | bigint unsigned | NO | PRI | NULL | auto_increment |
| template_id | bigint unsigned | NO | MUL | NULL | |
| label | varchar(80) | NO | | NULL | |
| name | varchar(80) | NO | | NULL | |
| type | varchar(10) | NO | | NULL | |
| order | int | NO | | NULL | |
| extended_options | text | YES | | NULL | |
| created_at | timestamp | YES | | NULL | |
| updated_at | timestamp | YES | | NULL | |
| deleted_at | timestamp | YES | | NULL | |
+------------------+-----------------+------+-----+---------+----------------+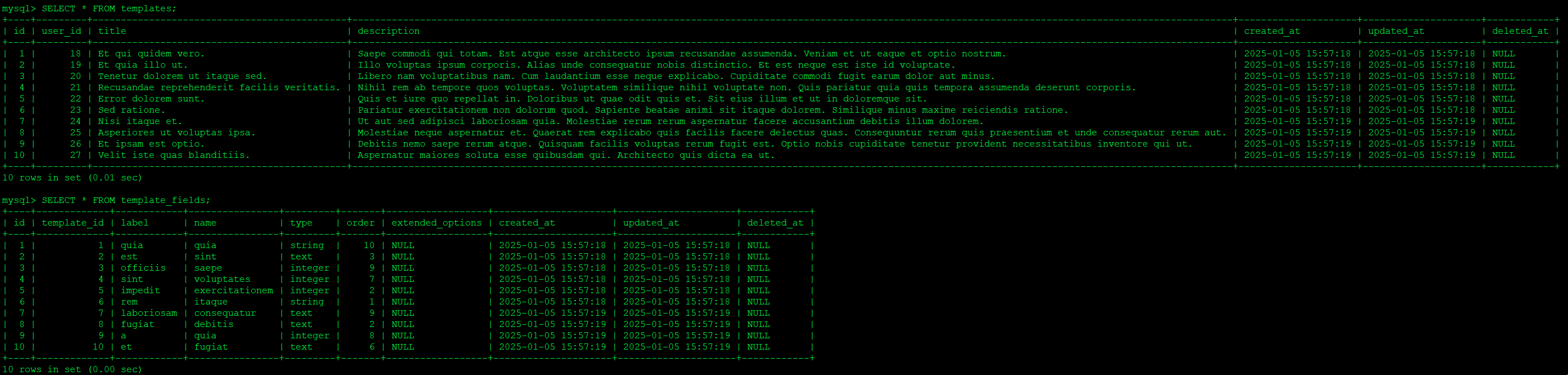
Looking at the structures and data in the tables, I think that everything makes sense. I’ve also added three basic unit tests to check the data access and relationships work as expected:
- We can access templates from a user object
- We can access fields from a template object
- We can load a template and its fields up into an object
With that, we’ve met all the acceptance criteria, and it’s time to get this code merged!
Commit And Merge
We now have some code. Depending on your strategy, maybe you’ve been committing as you go, or maybe you break it into blocks towards the end of your process. Either way, we’re going to be working in a branch.
Once the code has been pushed up to Github (or your code management tool of choice), we’re going to make a pull request, review it, then merge it. (I prefer squash and merge because it makes a cleaner history of changes).
Branch And Commit Naming
There are a lot of branch naming ideas, the one I go with is <ticket id>_<short work description>. It provides enough detail about the work, and traceability back to the source of work.
This leads us to a branch for this project named: US1-C1_create_database_tables
I usually advise to add your ticket ID in front of your commit messages as well, at very least when you merge to main. The reason for this is it makes every line easily trackable back to a specific request, which usually has more context to explain why the code exists.
Here are some example commit messages:
- US1-C1 Make the factory a little shorter
- US1-C1 Tweak database field lengths to be more reasonable
PR Sizing / Reviews
Common etiquette is to keep PR size on the smaller size, so as not to overload whomever might be reviewing your work. My recommendation is it should take on average less than 20 minutes to review a PR, and shouldn’t touch hundreds of files (for example, if you’re doing cleanup and making the same change in multiple places). These are only soft guidelines, but you want to both respect your reviewers’ time, and size your work so it can all be reviewed without losing their attention, and reduce the risk of errors getting through.
There are going to be large commits from time to time, because there will be changes that have to be done as one piece so they don’t break the system. By keeping our other commits small, we know that our reviewers will take the time needed to focus on these larger ones when we do make them.
Once our review is complete, we merge our pull request!
Wrapping Up
So in this post, we took our first card, and turned it into actual code. Writing about this work took a few hours instead of the usual 20–30 minutes, but this is the typical process for simple tasks.
As the work gets more advanced, there is more opportunity for back and forth discussion, and adjustments to what’s being done. As well, the task list definitely gets longer, but the general flow looks the same.
I hope that this was a good look into the developer workflow, and that you learned something! As always, I’d love for you to share your thoughts in the comments below!
Thanks for taking the time to read this, and stay tuned for the next part: Creating the template list page (US1-C2)
Cheers!
Leave a Reply